每日萝莉
基于ε-Greedy策略与Softmax函数的推荐机制
原文 发布于 Bangumi ~技术宅真可怕~本文遵循 CC BY 4.0 发布。
很久很久以前,希腊先贤苏菈带着她的小女儿去新年庙会,苏菈说「我们从庙会这头走到那头,不走回头路。你只可以选一家店买一个苹果糖,选定后就不能反悔哦」 走到尽头小女儿也没决定买哪家的苹果糖,她哭着说「因为只能选一次……我看到喜欢的苹果糖又担心后面有更好的……走到后面,才发现最好的我已经错过了……」 苏菈擦擦女儿的眼泪,说「(思考用时9s)假设有 n 个苹果糖,你应该先将前 n/e 个苹果糖作为参考,然后从第 n/e+1 个苹果糖开始,选择第一个比前面所有都更好的苹果糖即可」女儿哭得更大声了

#ε-Greedy策略:新作 vs 旧的佳作
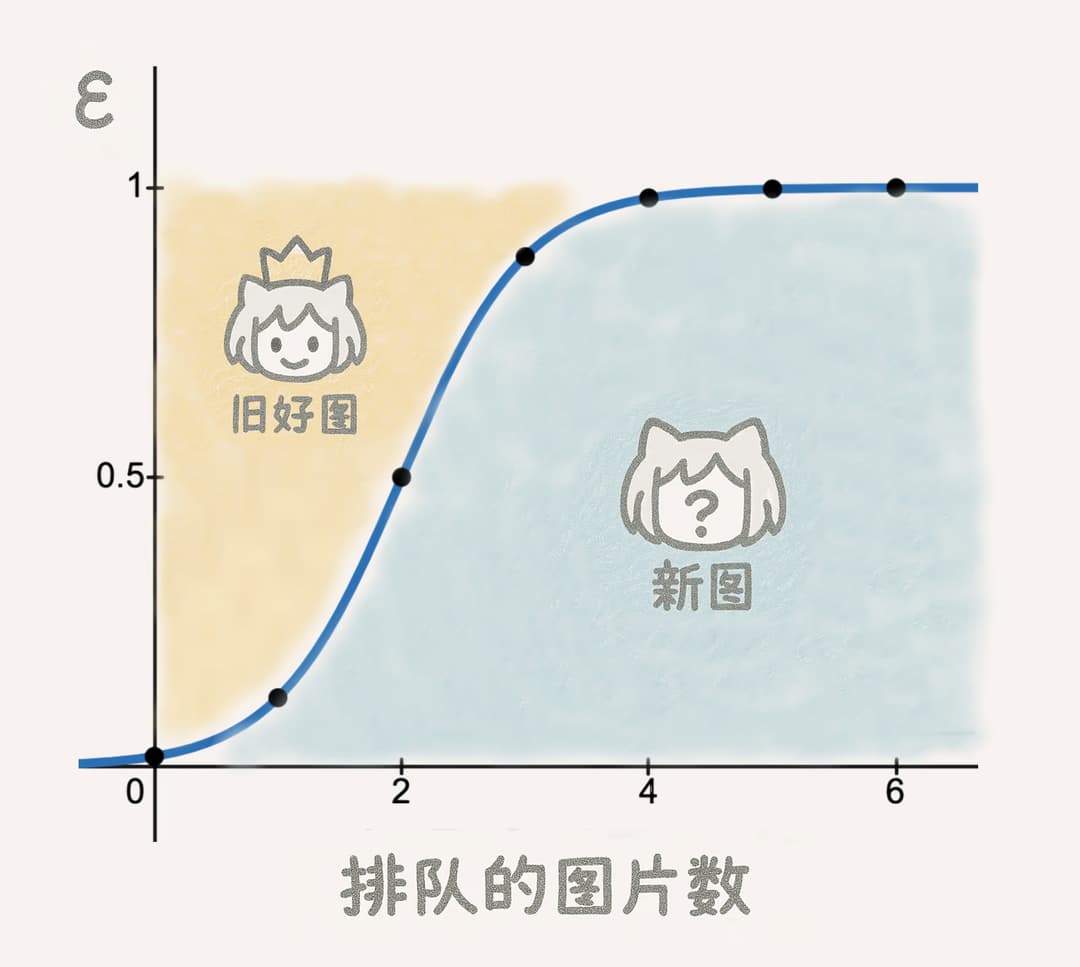
#Softmax函数:豪堪就要多多多多看
